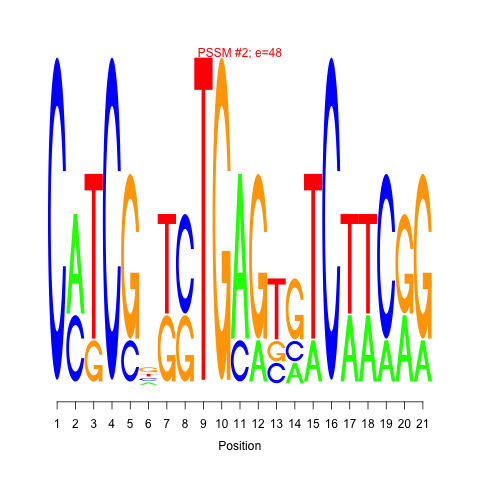
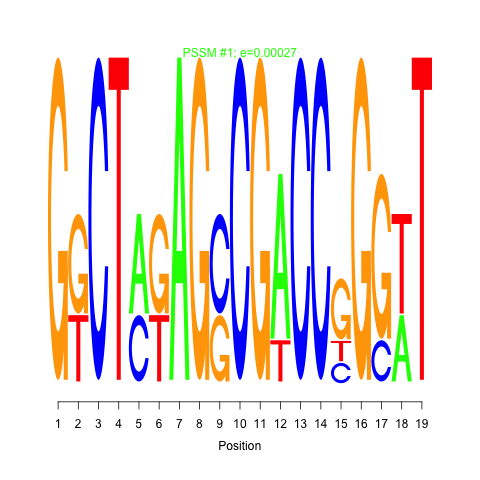Regulatory units (modules) are identified by using cMonkey algorithm. More specifically, module or bicluster refers to set of genes that are conditionally co-regulated under subset of the conditions. Identification of modules integrates co-expression, de-novo motif identification, and other functional associations such as operon information and protein-protein interactions.
Columns:
Title: Name of the regulatory module/bicluster identified by cMonkey and linked to module details page
Residual: is a measure of bicluster quality. Mean bicluster residual is smaller when the expression profile of the genes in the module is "tighter". So smaller residuals are usually indicative of better bicluster quality.
Score: Bicluster score.
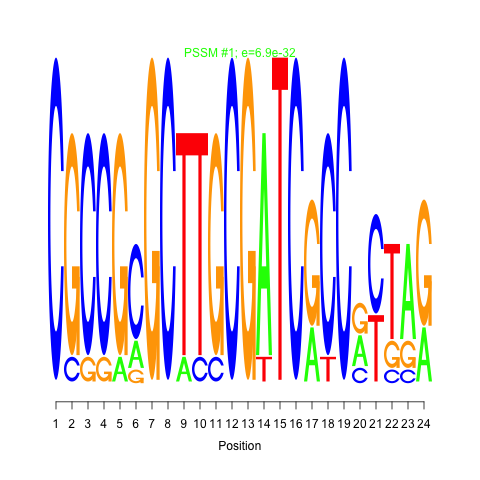
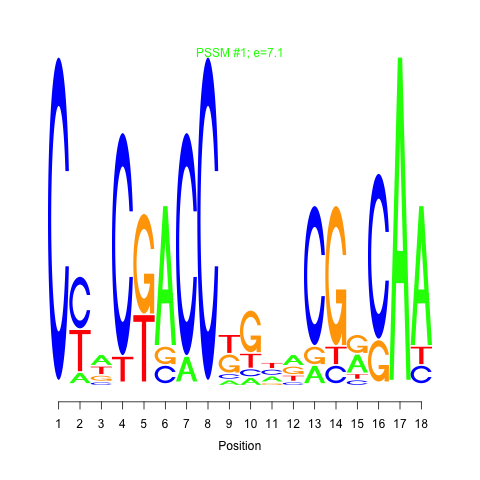
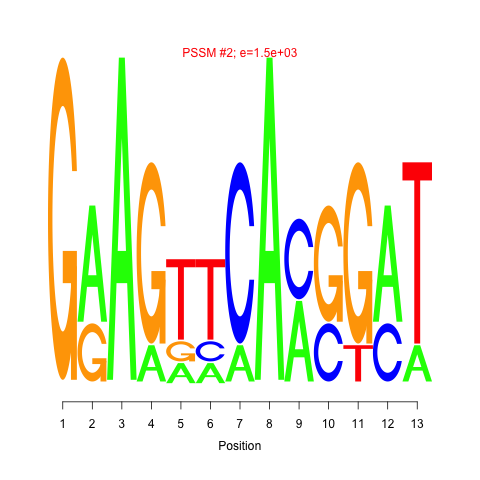
Motif 1 and 2: cMonkey integrates powerful de novo motif detection to identify conditionally co-regulated sets of genes. For each module 2 de novo predicted motifs are listed in the module page as motif logo images. Click on the image will show larger motif logo
Motif 1 and 2 e-values: Motif e-value is an indicative of the motif co-occurences between the members of the module. Smaller e-values are indicative of significant sequence motifs. Our experience showed that e-values smaller than 10 are generally indicative of significant motifs.
Filters: You can filter the rows in the table based on residual and motif e-values by using sliders.
Reference: Reiss, D. J., Baliga N. S., & Bonneau R. (2006). Integrated biclustering of heterogeneous genome-wide datasets for the inference of global regulatory networks. BMC bioinformatics. 7, 280