Organism : Bacillus subtilis | Module List:


Module 102 Profile
 Module member
Module member  Regulator
Regulator  Motif
Motif
Regulators for Module 102
There are 14 regulatory influences for Module 102
Motif information (de novo identified motifs for modules)
There are 2 motifs predicted.
| Motif Id | e-value | Consensus | Motif Logo |
|---|---|---|---|
| 5158 | 8.40e+00 | C.aCCTTTttc |
 |
| 5159 | 2.40e+03 | gGAaAggAg |
|
Functional Enrichment
Regulon 102 is enriched for following functions.
COG Enrichment Table
| Function Name | Function Type | Unadjusted pvalue | Benjamini& Hochberg pvalue | Genes with function | Method |
|---|---|---|---|---|---|
| Cell wall/membrane/envelope biogenesis | cog subcategory | 1.30e-02 | 2.07e-02 | 3/22 |
Members for Module 102
There are 22 genes in Module 102
| Name | Common name | Type | Gene ID | Chromosome | Start | End | Strand | Description | TF |
|---|---|---|---|---|---|---|---|---|---|
| BSU02530 | rtpA | CDS | None | chromosome | 277151 | 277312 | + | anti-TRAP regulator (RefSeq) | False |
| BSU05250 | ydeM | CDS | None | chromosome | 572518 | 572943 | + | putative dehydratase (RefSeq) | False |
| BSU08040 | yfjM | CDS | None | chromosome | 876934 | 877386 | + | hypothetical protein (RefSeq) | False |
| BSU08050 | yfjL | CDS | None | chromosome | 877416 | 878105 | + | hypothetical protein (RefSeq) | False |
| BSU09060 | yhcF | CDS | None | chromosome | 980574 | 980939 | + | putative transcriptional regulator (GntR family) (RefSeq) | True |
| BSU09440 | citA | CDS | None | chromosome | 1020365 | 1021465 | + | citrate synthase I (RefSeq) | False |
| BSU19220 | yocI | CDS | None | chromosome | 2093221 | 2094996 | - | putative ATP-dependent nucleic acid helicase (RefSeq) | False |
| BSU19480 | yojE | CDS | None | chromosome | 2122225 | 2123121 | - | putative integral inner membrane protein (RefSeq) | False |
| BSU19590 | ctpA | CDS | None | chromosome | 2131101 | 2132501 | - | carboxy-terminal processing protease (RefSeq) | False |
| BSU20040 | nrdF | CDS | None | chromosome | 2159179 | 2160976 | - | ribonucleotide-diphosphate reductase subunit beta (NCBI) | False |
| BSU21770 | ilvA | CDS | None | chromosome | 2291965 | 2293233 | - | threonine dehydratase (RefSeq) | False |
| BSU22030 | ypbR | CDS | None | chromosome | 2311726 | 2315307 | - | putative GTP-binding protein (RefSeq) | False |
| BSU22720 | cheR | CDS | None | chromosome | 2379545 | 2380315 | - | methyl-accepting chemotaxis proteins (MCPs) methyltransferase (RefSeq) | False |
| BSU23750 | yqjT | CDS | None | chromosome | 2467348 | 2467734 | - | putative lyase (RefSeq) | False |
| BSU23840 | yqjK | CDS | None | chromosome | 2477195 | 2478118 | - | ribonuclease Z (RefSeq) | False |
| BSU27200 | yrhG | CDS | None | chromosome | 2778689 | 2779489 | - | putative formate/nitrite transporter (RefSeq) | False |
| BSU31490 | pbpD | CDS | None | chromosome | 3232955 | 3234829 | + | penicillin-binding protein 4 (RefSeq) | False |
| BSU32630 | yurR | CDS | None | chromosome | 3351816 | 3352934 | - | putative oxidoreductase (RefSeq) | False |
| BSU34820 | bmrA | CDS | None | chromosome | 3576775 | 3578544 | - | efflux transporter (ATP-binding and permease protein) (RefSeq) | False |
| BSU35660 | mnaA | CDS | None | chromosome | 3663271 | 3664413 | - | UDP-N-acetylmannosamine 2-epimerase (RefSeq) | False |
| BSU37330 | argS | CDS | None | chromosome | 3832673 | 3834343 | - | arginyl-tRNA synthetase (RefSeq) | False |
| BSU38220 | ywcC | CDS | None | chromosome | 3921315 | 3921986 | - | putative transcriptional regulator (RefSeq) | True |
Help
What is a module?
Regulatory units (modules) in the Network Portal are based on the network inference algorithm used. For the current version, modules are based on cMonkey modules and Inferelator regulatory influences on these modules. More specifically, module refers to set of genes that are conditionally co-regulated under subset of the conditions. Identification of modules integrates co-expression, de-novo motif identification, and other functional associations such as operon information and protein-protein interactions.
Module Overview
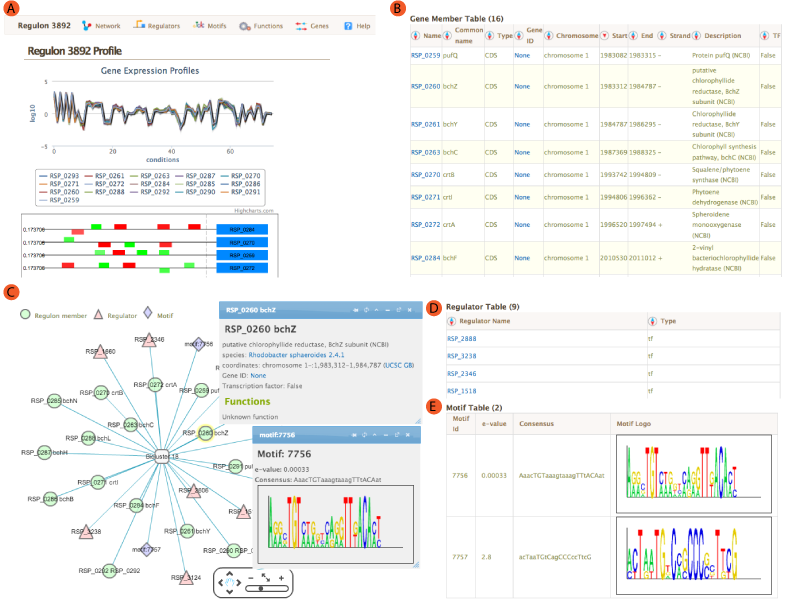
The landing module page shows quick summary info including co-expression profiles, de-novo identified motifs, and transcription factors and/or environmental factors as regulatory influences. It also includes module residual, motif e-values, conditions and links to other resources such as NCBI and Microbesonline. . If a transcription factor is included in the manually curated RegPrecise database, further information from RegPrecise is shown, allowing users to perform comparative analysis.
Expression Profiles
Expression profiles is a plot of the expression ratios (log10) of the module's genes, over all subset of the conditions included in the module. The X-axis represent conditions and the Y-axis represents log10 expression ratios. Each gene is plotted as line plot with different colors. Colored legend for the lines are presented under the plot. This plot is dynamic. Clicking on the gene names in the legend will show/hide the plot for that particular gene. A tooltip will show expression ratio information if you mouseover the lines in the plot.
Motif Locations
Location of the Identified motifs for the module in the upstream regions of the member genes are shown under the expression profiles plot. This plot shows the diagram of the upstream positions of the motifs, colored red and green for motifs #1, and 2, respectively. Intensity of the color is proportional to the significance of the occurence of that motif at a given location. Motifs on the forward and reverse strand are represented over and under the line respectively.
Network
A network view of the module is created using cytoscapeWeb and enables dynamic, interactive exploration of the module properties. In this view, module member genes, motifs, and regulatory influences are represented as peripheral nodes connected to core module node via edges. Module members are green circles, regulators are red triangles and motifs are blue diamonds. Selection of a node gives access to detailed information in a pop-up window, which allows dragging and pinning to compare multiple selections. Selecting module members will show information about the selected gene such as name, species and fucntions. Motif selection will show motif logo image and e-values. Bicluster selction will show expression profile and summary statistics for the module.
Module member Regulator Motif
Regulators
For each module, single or AND logic connected regulatory influences are listed under the regulators tab. These regulatory influences are identified by Inferelator. Table shows name of the regulator and its type. tf: Transcription factor, ef: Environmental factor and combiner:Combinatorial influence of a tf or an ef through logic gate. Tabel is sortable by clicking on the arrows next to column headers.
Motifs
Transcription factor binding motifs help to elucidate regulatory mechanism. cMonkey integrates powerful de novo motif detection to identify conditionally co-regulated sets of genes. De novo predicted motifs for each module are listed in the module page as motif logo images along with associated prediction statistics (e-values). The main module page also shows the location of these motifs within the upstream sequences of the module member genes.
Motifs of interest can be broadcasted to RegPredict (currently only available for Desulfovibrio vulgaris Hildenborough) in order to compare conservation in similar species. This integrated motif prediction and comparative analysis provides an additional checkpoint for regulatory motif prediction confidence.
Functions
Biological networks contain sets of regulatory units called functional modules that together play a role in regulation of specific functional processes. Connections between different modules in the network can help identify regulatory relationships such as hierarchy and epistasis. In addition, associating functions with modules enables putative assignment of functions to hypothetical genes. It is therefore essential to identify functional enrichment of modules within the regulatory network.
Functional annotations from single sources are often either not available or not complete. Therefore, we integrated KEGG pathway, Gene Ontology, TIGRFam and COG information as references for functional enrichment analysis.
We use hypergeometric p-values to identify significant overlaps between co-regulated module members and genes assigned to a particular functional annotation category. P-values are corrected for multiple comparisons by using Benjamini-Hochberg correction and filtered for p-values ≤ 0.05.
Network Portal presents functional ontologies from KEGG, GO, TIGRFAM, and COG as separate tables that include function name, type, corrected and uncorrected hypergeometric p-values, and the number of genes assigned to this category out of total number of genes in the module.
Genes
Gene member table shows all the genes included in the module. Listed attributes are;
- Name: Gene name or Locus tag
- Common Name: Gene short name
- Type: Type of the feature, usually CDS.
- Gene ID: Link to NCBI Gene ID
- Chromosome: Chromosome name from annotation file
- Start/End:Feature start and end coordinates
- Strand: strand of the gene
- Description: Description of the gene from annotation file
- TF: If the gene is a Transcription Factor or not.
If you are browsing the Network Portal by using Gaggle/Firegoose, firegoose plugin will capture the NameList of the gene members. Captured names can be saved into your Workspace by clicking on "Capture" in the firegoose toolbar or can be directly sent other desktop and web resources by using "Broadcast" option.
Definitions
Residual: is a measure of bicluster quality. Mean bicluster residual is smaller when the expression profile of the genes in the module is "tighter". So smaller residuals are usually indicative of better bicluster quality.
Expression Profile: is a preview of the expression profiles of all the genes under subset of conditions included in the module. Tighter expression profiles are usually indicative of better bicluster quality.
Motif e-value: cMonkey tries to identify two motifs per modules in the upstream sequences of the module member genes. Motif e-value is an indicative of the motif co-occurences between the members of the module.Smaller e-values are indicative of significant sequence motifs. Our experience showed that e-values smaller than 10 are generally indicative of significant motifs.
Genes: Number of genes included in the module.
Functions: We identify functional enrichment of each module by camparing to different functional categories such as KEGG, COG, GO etc. by using hypergeometric function. If the module is significantly enriched for any of the functions, this column will list few of the these functions as an overview. Full list of functions is available upon visiting the module page under the Functions tab.
Social
You can start a conversation about this module or join the existing discussion by adding your comments. In order to be able to add your comments you need to sign in by using any of the following services;Disqus, Google, Facebook or Twitter. For full compatibility with other network portal features, we recommend using your Google ID.