Organism : Desulfovibrio vulgaris Hildenborough
| Module List :


DVUA0014 glnB-3
nitrogen regulatory protein P-II
Functional Annotations (4)
| Function | System |
|---|---|
| Nitrogen regulatory protein PII | cog/ cog |
| regulation of nitrogen utilization | go/ biological_process |
| enzyme regulator activity | go/ molecular_function |
| Nitrogen metabolism | kegg/ kegg pathway |
 Module member
Module member  Regulator
Regulator  Motif
Motif
Regulation information for DVUA0014
(Mouseover regulator name to see its description)
| Regulator | Module | Operator |
|---|---|---|
| DVU0230 | 38 | tf |
| DVU0525 DVU0621 |
38 | combiner |
| DVU0539 | 38 | tf |
| DVU0653 DVU2251 |
38 | combiner |
| DVU1547 DVU2832 |
38 | combiner |
| DVU1572 DVU3255 |
38 | combiner |
| DVU1754 | 38 | tf |
| DVU2690 | 38 | tf |
| DVU3142 | 38 | tf |
| DVU3167 DVU0936 |
38 | combiner |
| DVUA0151 | 38 | tf |
| DVU0436 DVU0230 |
257 | combiner |
| DVU0619 DVU0230 |
257 | combiner |
| DVU0653 | 257 | tf |
| DVU1690 | 257 | tf |
| DVU2251 | 257 | tf |
| DVU2532 DVU3095 |
257 | combiner |
| DVU2582 DVU0230 |
257 | combiner |
| DVU2690 | 257 | tf |
| DVU3080 | 257 | tf |
| DVU3084 | 257 | tf |
| DVU3381 | 257 | tf |
| DVUA0024 | 257 | tf |
| DVUA0057 | 257 | tf |
| DVUA0151 | 257 | tf |
Motif information (de novo identified motifs for modules)
There are 4 motifs predicted.
Click on the RegPredict links to explore the motif in RegPredict.
| Motif Id | e-value | Consensus | Motif Logo | RegPredict |
|---|---|---|---|---|
| 75 | 4.70e+01 | tcCgAtGacGAaGg |
 |
RegPredict |
| 76 | 2.10e+04 | gCCGGTGC |
|
RegPredict |
| 489 | 4.20e+02 | tGaCaGtaGGCacggCaaaaG |
|
RegPredict |
| 490 | 2.80e+03 | .CagGtggCGcAgcTtC.tC |
|
RegPredict |
Functional Enrichment for DVUA0014
| Function | System |
|---|---|
| Nitrogen regulatory protein PII | cog/ cog |
| regulation of nitrogen utilization | go/ biological_process |
| enzyme regulator activity | go/ molecular_function |
| Nitrogen metabolism | kegg/ kegg pathway |
Module neighborhood information for DVUA0014
| Gene | Common Name | Description | Module membership |
|---|---|---|---|
| DVU0031 | AzlC family protein | 38, 211 | |
| DVU0180 | modC | molybdenum ABC transporter ATP-binding protein | 27, 38 |
| DVU0474 | ISDvu4, transposase | 257, 337 | |
| DVU0636 | response regulator/GGDEF domain-containing protein | 36, 38 | |
| DVU2097 | transcriptional regulator | 186, 257 | |
| DVU2732 | hypothetical protein DVU2732 | 38, 112 | |
| DVU2829 | hypothetical protein DVU2829 | 38, 247 | |
| DVU2830 | hypothetical protein DVU2830 | 38, 213 | |
| DVU2848 | tail fiber assembly protein | 38, 314 | |
| DVU2852 | tail protein | 38, 314 | |
| DVU2854 | tail protein | 38, 340 | |
| DVU2856 | hypothetical protein DVU2856 | 38, 314 | |
| DVU2868 | hypothetical protein DVU2868 | 32, 38 | |
| DVUA0008 | nitrogenase molybdenum-iron cofactor biosynthesis protein NifN | 257, 293 | |
| DVUA0014 | glnB-3 | nitrogen regulatory protein P-II | 38, 257 |
| DVUA0037 | sugar transferase domain-containing protein | 257, 335 | |
| DVUA0039 | chain length determinant family protein | 257, 328 | |
| DVUA0041 | hypothetical protein DVUA0041 | 257, 335 | |
| DVUA0045 | aminotransferase | 200, 257 | |
| DVUA0056 | hypothetical protein DVUA0056 | 47, 257 | |
| DVUA0062 | hypothetical protein DVUA0062 | 200, 257 | |
| DVUA0063 | Orn/DAP/Arg family decarboxylase | 200, 257 | |
| DVUA0065 | sensor histidine kinase | 257, 328 | |
| DVUA0066 | patatin family phospholipase | 38, 97 | |
| DVUA0090 | hypothetical protein DVUA0090 | 257, 335 |
Gene Page Help
Network Tab
If the gene is associated with a module(s), its connection to given modules along with other members of that module are shown as network by using CytoscapeWeb. In this view, each green colored circular nodes represent module member genes, purple colored diamonds represent module motifs and red triangles represent regulators. Each node is connected to module (Bicluster) via edges. This representation provides quick overview of all genes, regulators and motifs for modules. It also allows one to see shared genes/motifs/regulators among diferent modules.
Network representation is interactive. You can zoom in/out and move nodes/edges around. Clicking on a node will open up a window to give more details. For genes, Locus tag, organism, genomic coordinates, NCBI gene ID, whether it is transcription factor or not and any associated functional information will be shown. For regulators, number of modules are shown in addition to gene details. For motifs, e-value, consensus sequence and sequence logo will be shown. For modules, expression profile plot, motif information, functional associations and motif locations for each member of the module will be shown.
You can pin information boxes by using button in the box title and open up additional ones on the same screen for comparative analysis.
Regulation Tab
Regulation tab for each gene includes regulatory influences such as environmental factors or transcription factors or their combinations identified by regulatory network inference algorithms.
If the gene is a member of a module, regulators influencing that module are also considered to regulate the gene. Regulators table list total number of regulatory influences, regulators, modules and type of the influence.
You can see description of the regulator inside the tooltip when you mouseover. In certain cases the regulatory influence is predicted to be the result of the combination of two influences. These are indicated as combiner in the column labeled "Operator".
For transcription factors, an additional table next to regulator table will be show. This table show modules that are influenced by the transcription factor.
Motifs Tab
Network inference algorithm uses de novo motif prediction for assigning genes to modules. If there are any motifs identified in the upstream region of a gene, the motif will be shown here. For each motif sequence logo, consensus and e-value will be shown.
Functions Tab
Identification of functional enrichment for the module members is important in associating predicted motifs and regulatory influences with pathways. As described above, the network inference pipeline includes a functional enrichment module by which hypergeometric p-values are used to identify over representation of functional ontology terms among module members.
Network Portal presents functional ontologies from KEGG, GO, TIGRFAM, and COG as separate tables that include function name, type, corrected and uncorrected hypergeometric p-values, and the number of genes assigned to this category out of total number of genes in the module.
Module Members Tab
Identity of gene members in a module may help to identify potential interactions between different functional modules. Therefore, neighbor genes that share the same module(s) with gene under consideration are shown here. For each memebr, gene name, description and modules that contain it are listed.
Help Tab
This help page. More general help can be accessed by clicking help menu in the main navigation bar.
CircVis
Our circular module explorer is adapted from visquick originally developed by Dick Kreisberg of Ilya Shmulevich lab at ISB for The Cancer Genome Atlas. We use simplified version of visquick to display distribution of module members and their interactions across the genome. This view provides summary of regulation information for a gene. The main components are;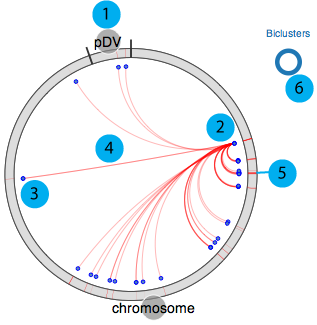
- 1. All genomic elements for the organism are represented as a circle and each element is separated by black tick marks. In this example chromosome and pDV represent main chromosome and plasmid for D. vulgaris Hildenborough, respectively.
- 2. Source gene
- 3. Target genes (other module members)
- 4. Interactions between source and target genes for a particular module
- 5. Module(s) that source gene and target genes belong to
- 6. Visualisation legend
Comments for DVUA0014
Please add your comments for this gene by using the form below. Your comments will be publicly available.comments powered by Disqus
Social Tab
Network Portal is designed to promote collaboration through social interactions. Therefore interested researchers can share information, questions and updates for a particular gene.
Users can use their Disqus, Facebook, Twitter or Google accounts to connect to this page (We recommend Google). Each module and gene page includes comments tab that lists history of the interactions for that gene. You can browse the history, make updates, raise questions and share these activities with social web.
In the next releases of the network portal, we are planning to create personal space for each user where you can share you space that contains all the analysis steps you did along with relevant information.